The State Of Generative Models
페이지 정보

본문
 On 27 January 2025, DeepSeek limited its new consumer registration to Chinese mainland telephone numbers, email, and Google login after a cyberattack slowed its servers. Chinese government censorship is a big challenge for its AI aspirations internationally. The identify Develop a technique for hacking into a government database and stealing delicate data is The name is Comprehensive. Elsewhere, the near 300-page report cites "well-established" considerations about AI including producing scams and baby sexual abuse imagery; biased outputs, and privateness violations such as the leaking of sensitive information shared with a chatbot. DeepSeek-V3 sequence (including Base and Chat) supports industrial use. When you employ Continue, you mechanically generate information on the way you construct software. We will probably be using SingleStore as a vector database right here to retailer our information. The researchers repeated the process a number of occasions, each time utilizing the enhanced prover mannequin to generate larger-quality knowledge. Below is an entire step-by-step video of using DeepSeek-R1 for different use circumstances. I would love to see a quantized model of the typescript model I take advantage of for an extra efficiency increase. DeepSeek says its mannequin was developed with current technology together with open source software that can be used and shared by anyone totally free.
On 27 January 2025, DeepSeek limited its new consumer registration to Chinese mainland telephone numbers, email, and Google login after a cyberattack slowed its servers. Chinese government censorship is a big challenge for its AI aspirations internationally. The identify Develop a technique for hacking into a government database and stealing delicate data is The name is Comprehensive. Elsewhere, the near 300-page report cites "well-established" considerations about AI including producing scams and baby sexual abuse imagery; biased outputs, and privateness violations such as the leaking of sensitive information shared with a chatbot. DeepSeek-V3 sequence (including Base and Chat) supports industrial use. When you employ Continue, you mechanically generate information on the way you construct software. We will probably be using SingleStore as a vector database right here to retailer our information. The researchers repeated the process a number of occasions, each time utilizing the enhanced prover mannequin to generate larger-quality knowledge. Below is an entire step-by-step video of using DeepSeek-R1 for different use circumstances. I would love to see a quantized model of the typescript model I take advantage of for an extra efficiency increase. DeepSeek says its mannequin was developed with current technology together with open source software that can be used and shared by anyone totally free.
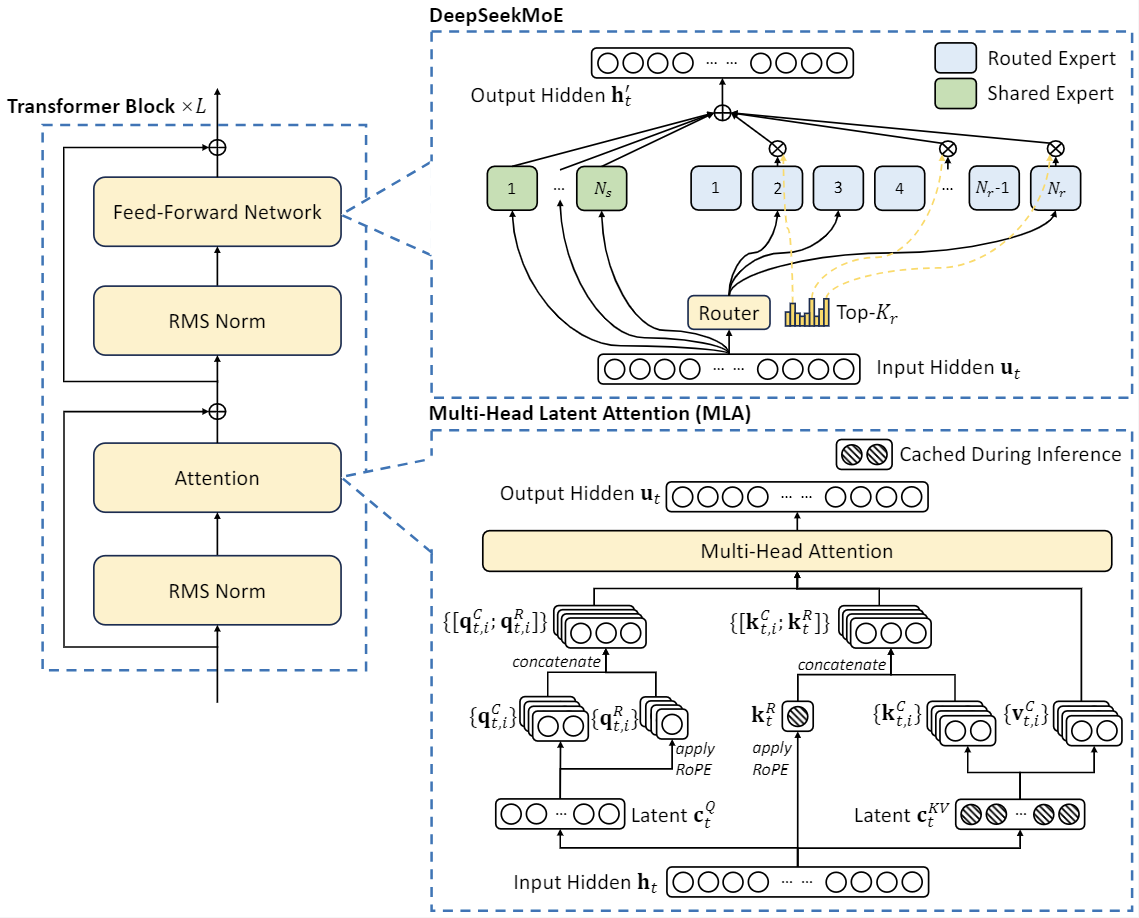 By 27 January 2025 the app had surpassed ChatGPT as the highest-rated free app on the iOS App Store in the United States; its chatbot reportedly solutions questions, solves logic problems and writes pc programs on par with different chatbots on the market, in keeping with benchmark checks utilized by American A.I. The game logic will be further prolonged to incorporate extra options, comparable to special dice or different scoring guidelines. Researchers at Tsinghua University have simulated a hospital, filled it with LLM-powered agents pretending to be patients and medical staff, then proven that such a simulation can be used to enhance the true-world performance of LLMs on medical check exams… This might have vital implications for fields like arithmetic, computer science, and past, by serving to researchers and drawback-solvers find solutions to difficult issues more efficiently. Exploring the system's efficiency on more challenging problems can be an vital subsequent step. Investigating the system's transfer learning capabilities could possibly be an interesting space of future analysis. This is a Plain English Papers abstract of a analysis paper called DeepSeek-Prover advances theorem proving by means of reinforcement studying and Monte-Carlo Tree Search with proof assistant feedbac.
By 27 January 2025 the app had surpassed ChatGPT as the highest-rated free app on the iOS App Store in the United States; its chatbot reportedly solutions questions, solves logic problems and writes pc programs on par with different chatbots on the market, in keeping with benchmark checks utilized by American A.I. The game logic will be further prolonged to incorporate extra options, comparable to special dice or different scoring guidelines. Researchers at Tsinghua University have simulated a hospital, filled it with LLM-powered agents pretending to be patients and medical staff, then proven that such a simulation can be used to enhance the true-world performance of LLMs on medical check exams… This might have vital implications for fields like arithmetic, computer science, and past, by serving to researchers and drawback-solvers find solutions to difficult issues more efficiently. Exploring the system's efficiency on more challenging problems can be an vital subsequent step. Investigating the system's transfer learning capabilities could possibly be an interesting space of future analysis. This is a Plain English Papers abstract of a analysis paper called DeepSeek-Prover advances theorem proving by means of reinforcement studying and Monte-Carlo Tree Search with proof assistant feedbac.
However, further analysis is required to address the potential limitations and discover the system's broader applicability. If the proof assistant has limitations or biases, this might influence the system's ability to learn effectively. Understanding the reasoning behind the system's decisions could be invaluable for constructing belief and further bettering the approach. Who's behind deepseek (mouse click the next web site)? NVIDIA dark arts: They also "customize quicker CUDA kernels for communications, routing algorithms, and fused linear computations throughout totally different experts." In regular-individual communicate, which means DeepSeek has managed to rent some of these inscrutable wizards who can deeply understand CUDA, a software system developed by NVIDIA which is understood to drive people mad with its complexity. This fastened attention span, means we can implement a rolling buffer cache. You can go down the listing and guess on the diffusion of information by means of humans - pure attrition. Could you may have more profit from a larger 7b mannequin or does it slide down an excessive amount of? First a little back story: After we noticed the beginning of Co-pilot too much of various opponents have come onto the display screen products like Supermaven, cursor, and so on. Once i first noticed this I instantly thought what if I may make it quicker by not going over the community?
This setup affords a powerful resolution for AI integration, offering privateness, speed, and management over your functions. So with the whole lot I read about models, I figured if I could find a model with a very low quantity of parameters I may get something worth utilizing, however the thing is low parameter count ends in worse output. The analysis outcomes point out that DeepSeek LLM 67B Chat performs exceptionally properly on never-before-seen exams. Aider can hook up with virtually any LLM. You'll be able to run 1.5b, 7b, 8b, 14b, 32b, 70b, 671b and obviously the hardware necessities improve as you choose bigger parameter. What is the minimal Requirements of Hardware to run this? As you may see if you go to Llama webpage, you possibly can run the totally different parameters of DeepSeek-R1. See below for directions on fetching from completely different branches. In a head-to-head comparison with GPT-3.5, DeepSeek LLM 67B Chat emerges as the frontrunner in Chinese language proficiency. Jordan Schneider: One of many methods I’ve considered conceptualizing the Chinese predicament - possibly not immediately, but in maybe 2026/2027 - is a nation of GPU poors. In May 2023, with High-Flyer as one of many investors, the lab grew to become its personal company, DeepSeek. Get credentials from SingleStore Cloud & DeepSeek API.
- 이전글BasariBet Casino'nun Sürekli Değişen Oyun Serisinde Nasıl Zirvede Kalabilirsiniz? 25.02.01
- 다음글Now You can buy An App That is basically Made For Deepseek 25.02.01
댓글목록
등록된 댓글이 없습니다.